

В продолжение темы коммодицикации науки.
Бернадотт Александра1,2
1Faculty of Mechanics and Mathematics, Lomonosov Moscow State University, Leninskie gory 1, Moscow, 119991, Russian Federation.
2Division of Physiological Chemistry I, Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Scheeles väg 2, S-171 77 Stockholm, Sweden.
Введение
Научная гипотеза всегда выходит за пределы фактов,
послуживших основой для ее построения.
В. И. Вернадский
В 1996 году Джон Хорган опубликовал переизданную несколько раз книгу под названием «Конец науки» (The End of Science [2]), где он размышлял о смерти науки, о тенденциях, которые свидетельствуют о значительном изменении качества научного знания.
Действительно, в настоящее время многие из ученых, ретроспективно отслеживая предмет своих исследований, интуитивно замечают небольшие, а иногда даже довольно резкие изменения, произошедшие в научном мире, начиная с конца 1980-х годов. Изменения эти затрагивают все составляющие науки, включая семантику, методологию, аксиоматические основы и даже научные цели.
Исходя из предположения, что научный текст отражает тенденции в научном мире, имеет смысл проанализировать публикации в научных журналах, соответствующие предполагаемому периоду трансформации в науке. В настоящей публикации представлены результаты анализа полнотекстовых публикаций журнала «Science» за период с 1996 по 2017 гг.
Прежде чем представить методы, положенные в основу такого анализа, и его результаты, опишем интуитивно воспринимаемые тенденции в науке, к которым приводит беглый, неформальный анализ публикуемых результатов исследований.
Нарушенное равновесие теории и практики
Содержание
Исходя из неформализованного наблюдения за большим объемом опубликованных научных статей можно выделить несколько тенденций. Одной из текущих научных тенденций является существенный сдвиг от теории к практике, с акцентом на эмпирическую составляющую в исследованиях. «Пустое теоретизирование» в таком подходе к исследованиям со временем действительно может оказаться пустым множеством. Теоретические подходы, по мнению некоторых современных исследователей уходят из науки как невостребованные временем и практикой.
Cубъективная оценка позволяет также говорить о потере среди ученых интереса к строгому структурированию научных идей, систематизации знаний, аксиоматизации, к формированию на этой основе новых парадигм. Именно разный методологический подход к научному познанию отличает «творцов»-ученых от «ремесленников»-ученых. Такое отличие в непосредственном приложении к науке хорошо отражено в английских словах «researcher» и «scientist».
Одновременно с потерей интереса к теоретическому подходу в исследованиях, наблюдается снижение использования соответствующего ему строгого формализованного метода исследования. В целом можно говорить о потере интереса к дедуктивным методам познания. Для подтверждения этого приведем выдержку из статьи 2010 года журнала «Nature Reviews. Microbiology». В этом издании, которое определяет тенденции научных исследований в микробиологии познания, была опубликована статья под названием «Пирамида знаний» («The pyramid of knowledge») доктора Верникоса [5]. В статье он декларирует следующее:
«дедуктивные методы обычно используются при недостатке рабочих данных и [они] не могут быть полностью аналитическими, тогда как индуктивный подход в конечном итоге приводит к более реалистичному пониманию общей картины» [5].
Эта выдержка демонстрирует позицию автора, который отдает предпочтение аналитическим методам, рассматривая метод синтеза и дедукции как нечто ошибочное и ущербное, способное лишь закрыть дыры научного знания в ожидании экспериментальных данных. В данной статье «правильное» научное познание описывается движением снизу вверх без особого плана и проекта, то есть «наощупь». Кроме того, в этой работе отражен текущий сдвиг науки от теории к эксперименту.
Изменение научной картины мира не обходится без последствий. Последствием нарушения ранее существовавшего равновесия между теорией и эмпирикой является фрагментация знаний, обрывочность и бессистемность научного поиска и менее глубокое погружение ученых в суть исследуемого объекта. Это и является причиной кризиса идеи, кризиса принятой ранее парадигмы.
Фундаментальные и прикладные науки в посткапиталистическую эпоху
Вторая тенденция изменения в науке, напрямую связанная с превалированием практического знания над теоретическим, заключается в том, что существующее смещение в исследованиях от фундаментальных к прикладным, сопровождается их быстрым переходом на рельсы коммерциализации. Поскольку фундаментальная наука нуждается в долгосрочных инвестициях, она становится невыгодной в капиталистическом мире «высоких» скоростей и быстрых дивидендов. Такая инволюция в науке привела к изменению научной картины в целом. В 2015 году в журнале «Nature» ученые формулируют проблему следующим образом:
«Ученые, которые консультируют политиков, имеют два варианта: быть прагматичными или игнорируемыми» («Scientists who advise politicians have two options: to be pragmatic or neglected») [1].
Можно выделить следующие следствия перемещения основного акцента от фундаментальных исследований к прикладным и к их коммерческому применению. Во-первых, это потеря фундаментальной основы научных знаний по отношению к различным областям наук, которая объединяет и обеспечивает связь между этими областями. Во-вторых, происходит реконструкция базовых системообразующих парадигм познания и общих научных законов. Новые научные знания требуют постоянной эволюции и пересмотра их системообразующих парадигм, однако с учетом сдвига акцента исследований, новые парадигмы не появляются. В-третьих, как следствие тенденции к коммерциализации науки и стремления к быстрой практической реализации исследований, формируется потребительское отношение на всех уровнях научного сообщества, включая соответствующее такому отношению профессиональную этику. Данные изменения приводят к профессиональной стагнации и, как следствие, к утрате научного потенциала.
Кроме представленных выше тенденций, можно усмотреть признаки глобализации в науке. Помимо резко возросшей частоты использования слов с корнем «глобал», признаками глобализации в научном мире являются: утрата научных школ; появление головного научного центра с функцией цензора; формирование подчиненных транснациональных исследовательских центров, как правило, ограниченных экономически и юридически. Это обстоятельство приводит к эффектам застоя и самоторможения в науке, к определению её статуса как вторичного, зависящего от практической её востребованности.
Формальная постановка цели и задач исследования
Целью исследования, результаты которого представлены в настоящей публикации: в первом приближении продемонстрировать тенденции изменения научного знания в отношении теории, практики, фундаментального и прикладного знания; продемонстрировать тенденции к коммерциализации науки и появлению элементов её политизированности.
К задачам такого исследования относятся следующие:
1) предложить метод кластеризации документов с использованием заданного списка слов;
2) исходя из предположения, что научные тенденции коррелируют с изменением использования определенных слов и фраз в научных статьях, проанализировать опубликованные работы высокорейтингового в современной мировой науке журнала «Science» на период с 1996 по 2017 год.
Методы исследования
Для формирования корпуса текстов было проанализировано хранилище веб-ресурсов журнала «Science» (http://www.sciencemag.org) за 20 лет. При этом был реализован автоматизированный сбор статей скриптом, написанным на языке Python 3, с использованием библиотек: Requests; urllib2; selenium libraries с интеграцией браузеров Selenium и Firefox.
Предварительная стандартизация (токенизация, лемматизация, ликвидация стоп-слов) и формирование корпуса слов
Как предварительная подготовка к формированию корпуса слов была проведена токенизация текстов (разбиение текста на более мелкие части — токены) на отдельные слова.
Далее был сформирован предварительный корпус из токенов (отдельных слов в различной падежной форме).
На следующем шаге корпус токенов был лемматизирован – изоформы (производные слов) были объединены в один лингвистический стержень (пул) путем сведения слов к определенной общей словарной корневой форме. Для этой цели использовали корпус WordNet® (http://wordnet.princeton.edu), английскую лексическую базу данных и библиотеку с открытым исходным кодом Natural Language Toolkit (NLTK) (http://www.nltk.org/) для программирования на языке Python 3. Корпус WordNet® состоит из 117 000 синсетов (когнитивных синонимов), объединенных в ограниченное число понятий (логически связанных групп терминов).
Из полученного корпуса лемматизированных слов убирались наиболее распространенные слова (стоп-слова) английского языка (местоимения, статьи, союзы и предлоги), которые были отфильтрованы с использованием библиотеки NLTK с корпусом из 128 английских стоп-слов.
На основе собранных текстов и полученного корпуса лемматизированных слов был сформирован используемый в анализе корпус слов размером 200 тыс слов.
Формирование классов слов
На первом этапе из корпуса слов подбирались слова с нужным семантическим значением, то есть слова, относящиеся к одной из следующих областей: фундаментальная наука; прикладная наука; теоретическое знание; практическое знание; коммерция; политика. Из этих слов создавались классы слов: «теоретический» и «фундаментальный» слово-классы; «прикладной» и «практический» слово-классы; «коммерческий» слово-класс; «политический» слово-класс.
Для создания перечисленных выше классов слов, во-первых, определялись центры этих классов, которые содержали по несколько ключевых слов, характеризующих каждую из областей: фундаментальная наука; прикладная наука; теоретическое знание; практическое знание; коммерция; политика.
Во-вторых, основываясь на словах из центров слово-классов, в автоматическом режиме в корпусе полнотекстовых статей производился поиск парных слов, которые появлялись со словами из центра слово-класса в одном предложении. Таким образом каждое слово из центра слово-класса образовывало несколько сотен пар слов, в которых одно слово относилось к центру слово-класса, а другое — встречалось с этим словом в одном предложении во всем корпусе полнотекстовых статей.
В-третьих, производился учет совместной вероятности каждой такой пары слов, используя для этого модель «Pointwise Mutual Information» [6]:
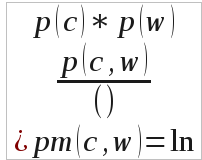 где p(c) — вероятность появления слова из центра слово-класса в полном корпусе статей; p (w) — вероятность появления другого слова из пары в полном корпусе статей, p(c, w) – вероятность нахождения обоих слов в одном предложении, рассчитанная на полном корпусе статей; pm(c, w) — совместная вероятность слов центра p(c) и слов первого круга p(w). Здесь под словами первого круга для каждого слово-класса понимаются слова, составляющие со словами из центра слово-класса пары с высокой совместной вероятностью.
где p(c) — вероятность появления слова из центра слово-класса в полном корпусе статей; p (w) — вероятность появления другого слова из пары в полном корпусе статей, p(c, w) – вероятность нахождения обоих слов в одном предложении, рассчитанная на полном корпусе статей; pm(c, w) — совместная вероятность слов центра p(c) и слов первого круга p(w). Здесь под словами первого круга для каждого слово-класса понимаются слова, составляющие со словами из центра слово-класса пары с высокой совместной вероятностью.
В-четвертых, таким же образом предварительно определив как центр слова первого круга, находили второй круг слов.
Разделить «теоретический» и «фундаментальный» классы не представлялось возможным, поэтому эти слово-классы были объединены в один слово-класс. По той же причине два слово-класса «прикладной» и «практический» были слиты в один.
После выполнения описанных выше расчётов, получили кластера слов, характеризующих классы: «фундаментальный» («теоретический») слово-класс; «практический» («прикладной») слово-класс; «политический» слово-класс и «коммерческий» слово-класс.
Векторная модель представления документа
Текстовый документ представлялся вектором слов, для формирования которого использовалась классическая tf-idf – модель (term frequency — inverse document frequency) [3], позволяющая присвоить большой вес словам, которые встречались с высокой частотой в пределах одной статьи, но имели низкую частоту встречаемости в пределах всего корпуса статей. Таким образом модель позволяла выделять слова, обладающие высокой специфичностью для отдельной статьи.
Мера tf-idf вычислялась по формуле:
![]()
где t – слово, d – статья в корпусе статей, D – корпус полнотекстовых статей.
В данной модели tf (term frequency — частота слова) — отношение числа появлений некоторого слова в статье к общему числу слов статьи, что показывало уровень специфики данного слова для статьи. Такая частота определялась по формуле:
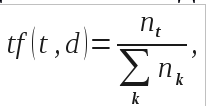 где – число появлений слова t в статье; в знаменателе – общее число слов в статье.
где – число появлений слова t в статье; в знаменателе – общее число слов в статье.
В используемой модели idf (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в корпусе статей. Эта величина уменьшает вес не обладающих спецификой, часто встречающихся в корпусе слов, и рассчитывается по формуле:
где 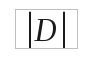 - число статей в корпусе статей,
- число статей в корпусе статей,  – число статей в корпусе статей, в которых встречается слово t.
– число статей в корпусе статей, в которых встречается слово t.
Далее для каждой статьи в корпусе статей строился вектор значений tf-idf как по общему корпусу слов, так и отдельно по каждому слово-классу, так как задачей было не само разделение документов, а разделение документов согласно определенному принципу.
Метод главных компонент
Для понижения размерности пространства данных статей, представленных в виде вектора значений tf-idf, использовался анализ главных компонент.
Полученные для статей вектора значений tf-idf размерности 10-200 тыс переводили в 5-мерное линейное многообразие методом главных компонент с использованием библиотеки Sklearn для Python 3 (http://scikit-learn.org/stable/index.html Размерность была подобрана эмпирически с учетом последующей кластеризации. А именно: повышение и понижение размерности линейного многообразия не давало эффекта при последующей кластеризации методом k-средних – не улучшало разделение на два кластера.
Метод k-средних
Методом k-средних [4] кластеризовались данные статьей, представленные по двум слово-классам: «фундаментальный» («теоретический») слово-класс; «практический» («прикладной») слово-класс. Отдельно данные кластеризовались по «политическому» слово-классу и «коммерческому» слово-классу. Кластеризация для каждой задачи проводилась не менее 5 раз.
Использована библиотека Scipy для Python 3, k выбирали равным 2 с возможностью пересечений кластеров.
Результаты
Используя описанный выше автоматизированный режим сбора текстов был сформирован корпус полнотекстовых статей, опубликованных в журнале «Science» с 1996 по 2017 год. Корпус статей состоит из 16 тысяч научных публикаций (по 500-1 500 слов каждая), хранящихся в виде отдельного текстового документа на локальном сервере.
Корпус слов формировался на основе лемматизированных слов. Объем корпуса составил 200 тысяч слов.
Предварительная визуализация данных
Простой анализ частоты слов показал, что частота употребления слов в научном тексте изменилась за последние 20 лет в публикациях журнала «Science». Наиболее отчетливо это прослеживается на словах из «коммерческого» слово-класса.
На рисунке 1 прослеживается постепенное увеличение частоты встречаемости слов из «коммерческого» слово-класса со временем, косвенно отражающее тенденцию к коммерциализации науки. Для примера были выделены следующие слова: «стоимость», «прибыль», «банк», «коммерция», «инвестирование», «деньги», «капитал», «фонд», «финансы», «грант», «прибыль», «доллар», «евро», «продавец», «покупка», «покупатель» (‘cost’, ‘benefit’, ‘bank’, ‘commerci’, ‘invest’, ‘money’, ‘capit’, ‘fund’, ‘financ’, ‘grant’, ‘profit’, ‘dollar’, ‘euro’, ‘seller’, ‘buy’, ‘buyer’ – слова приведены в лемматизированной форме).
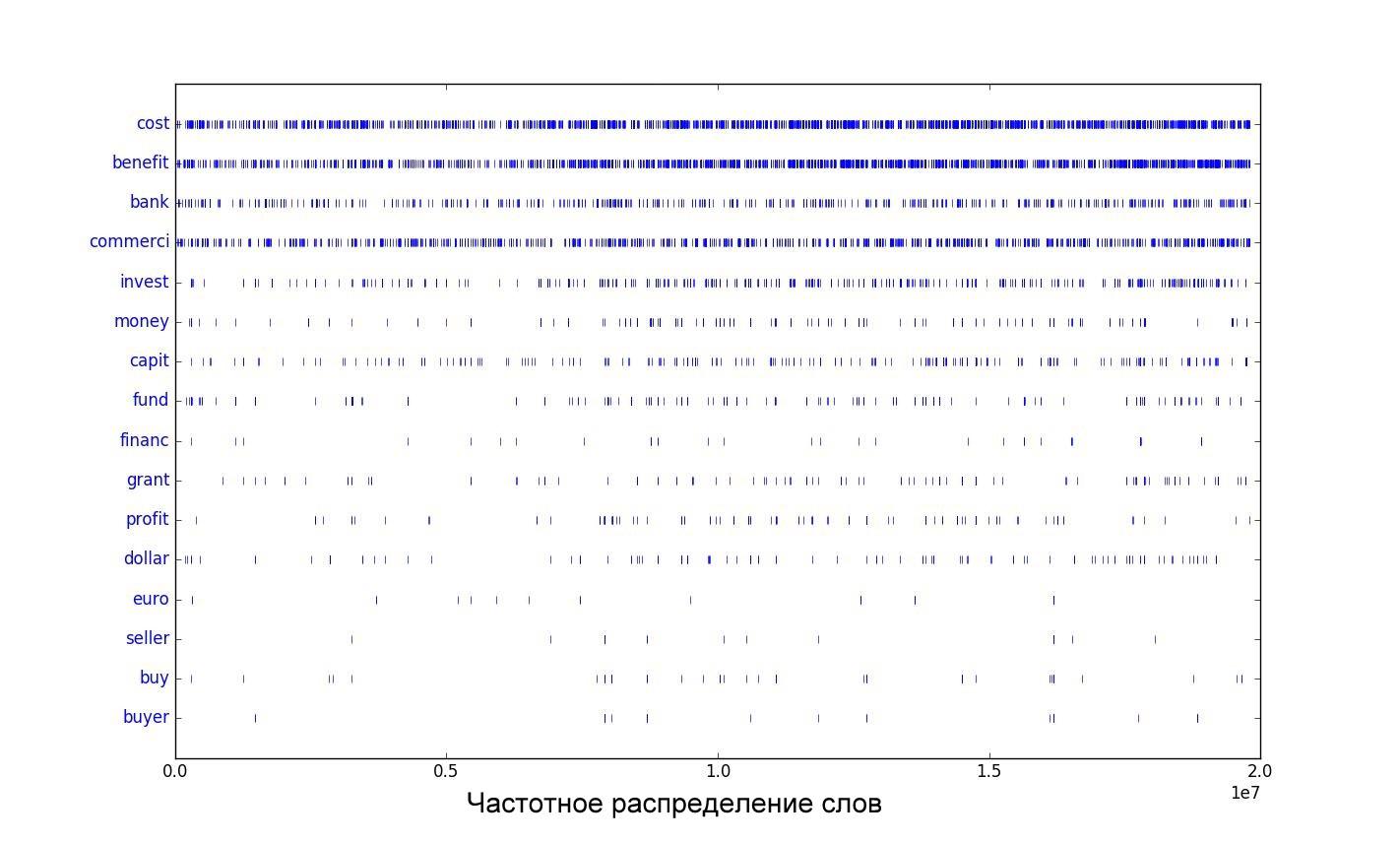
Рис. 1. Частотное распределение некоторых cлов (приведенных к основной форме), входящих в «коммерческий» слово-класс по годам. На оси абсцисс 0.0 соотвествует 1996 году, 2.0 – 2017. Каждой вертикальной черте соответсвует появление слова в тексте. Текст был представлен последовательной склейкой статей в соответствии с их появлением с 1996 по 2017 год.
Анализ главных компонент
Используя анализ главных компонент, были выделены основные компоненты для анализа статей, представленных в виде tf-idf векторов.
На рисунке 2 можно наблюдать тенденцию к смещению употребления слов на примере полного корпуса слов «политического», «коммерческого» слово-классов, а также «фундаментального» («теоретического») и «практического» («прикладного») слово-классов.
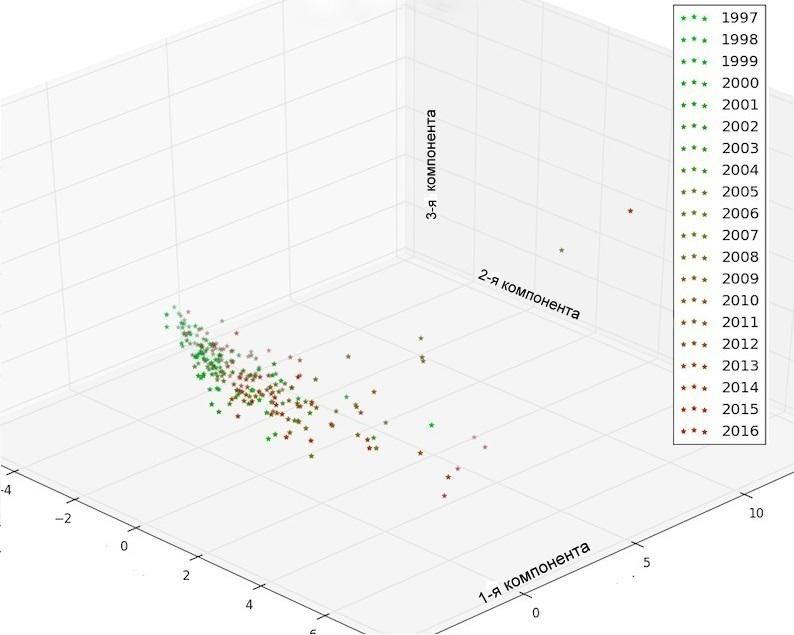
Рис.2а. Анализ главных компонент tf-idf векторов, построенных на всем корпусе слов. Каждой точке соответсвует 50 статей. Оси соотвествуют главным компонентам (1-3 и 1-2 соответственно)
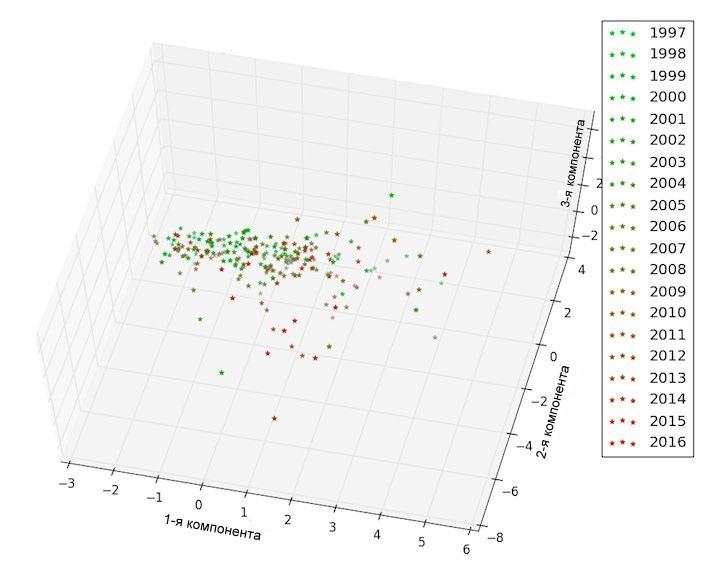
Рис.2б. Анализ главных компонент tf-idf векторов, построенных на фундаментальном (теоретическом) и практическом (прикладном) слово-классах. Каждой точке соответсвует 50 статей. Оси соответствуют главным компонентам (1-3 и 1-2 соответственно).
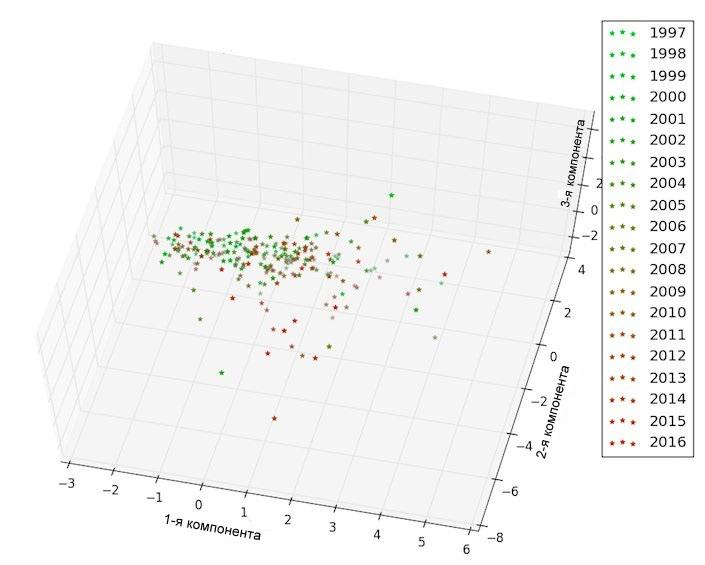
Рис.2в. Анализ главных компонент tf-idf векторов, построенных на «коммерческом» слово-классе. Каждой точке соответствует 50 статей.
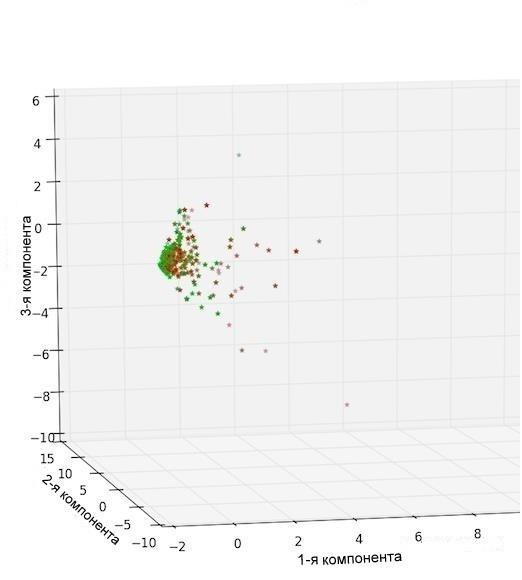
Рис.2г. Анализ главных компонент tf-idf векторов, построенных на «политическом» слово-классе. Каждой точке соответствует 50 статей.
Кластеризация документов на основе слово-классов
После кластеризации документов методом k-средних (k = 2) на основе векторов на базе «фундаментального» («теоретического») и «практического» («прикладного») слово-классов были получены два кластера достаточно хорошо (согласно принятой методике) разделяемых научных статей.
Первый кластер соответствовал теоретическим и фундаментальным статьям, его центр тяжести находится в области 1999-2000 годов. Второй кластер, соответствующий прикладным (практическим) научным статьям имеет центр тяжести в области 2010 года (рис. 3).
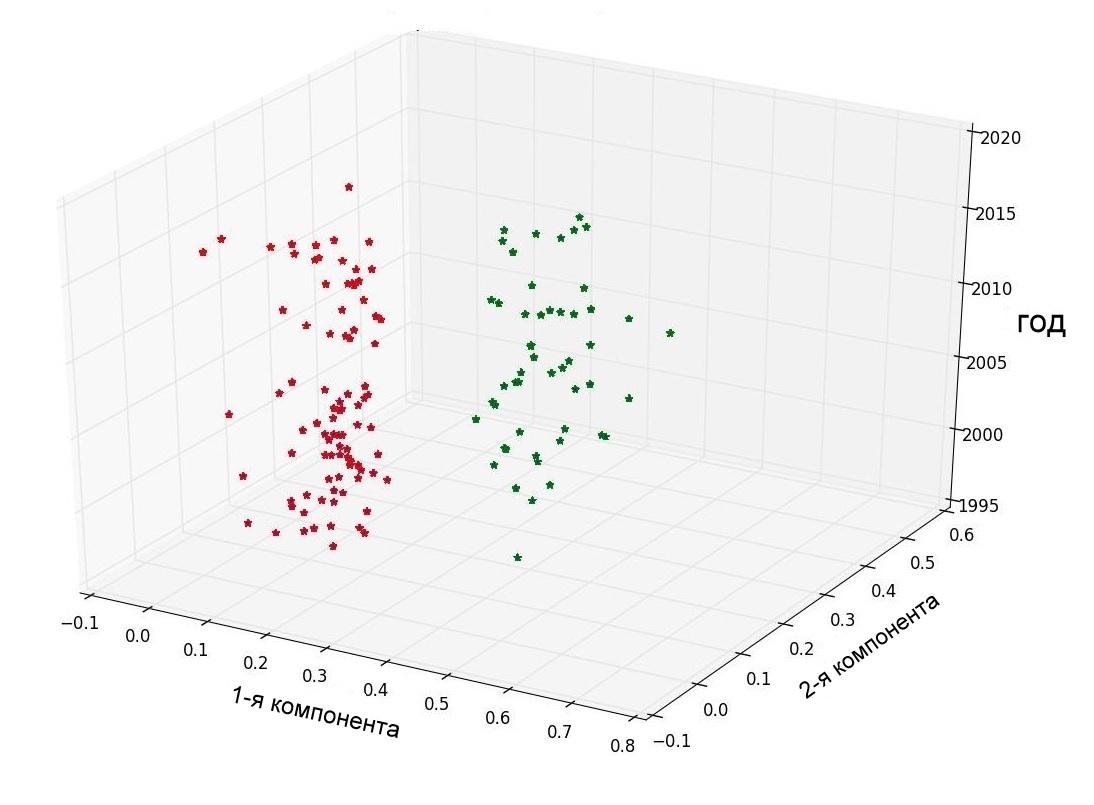
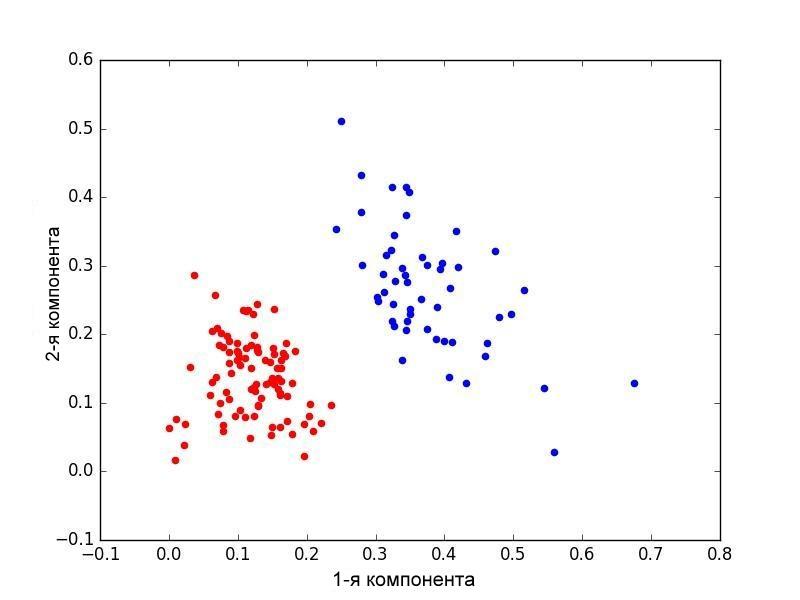
Рис.3. Метод k-средних. Кластер соответсвующий фундаментальным (теоретическим) документам отмечен красным. Синим и зеленым отмечен кластер соотвествующий статьям практического(прикладного) содержания. Каждой точке соответствует 50 статей. Оси соответствуют главным компонентам (1-3 и 1-2 соответственно).
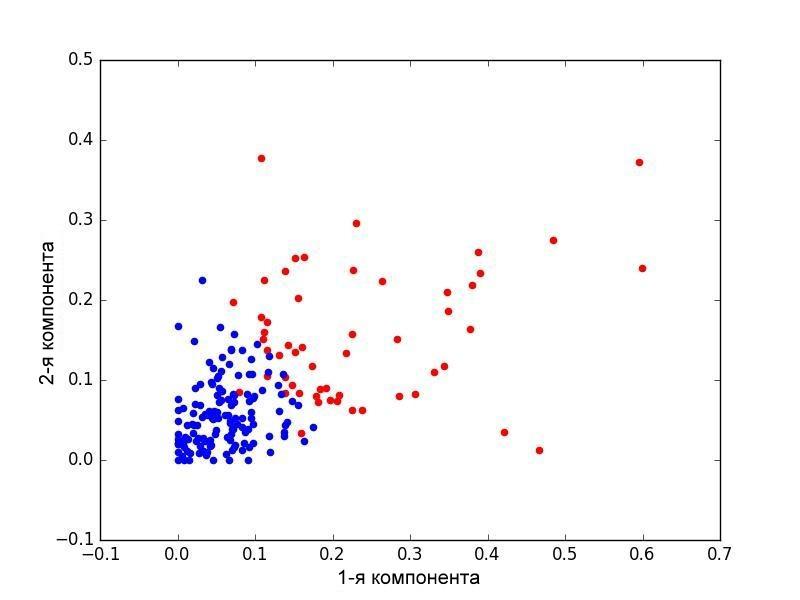
Кластеризация статей, представленных в виде векторов на основе «коммерческого» слово-класса показала, что статьи могут быть разбиты на два пересекающихся кластера.
Кластер документов, характеризующийся превалированием слов из «коммерческого» и «политического» слово-классов, имел центр тяжести в области 2010 года, тогда как кластер статей «некоммерческой» и «деполитизированной» направленности имел центр тяжести в области 1999 года (рис.4).

Рис.4. Метод k-средних. Кластер соответствующий документам c превалированием слов из коммерческого слово-класса отмечен красным. Синим и зеленым отмечен кластер соотвествующий статьям некоммерческой направленности. Каждой точке соответсвует 50 статей. Оси соотвествуют 1-2 главным компонентам и году (на левом рисунке).
Заключение
В настоящей статье приведен новый метод кластеризации научных документов, позволяющий разделить текстовые документы, опираясь на определенные семантические потребности. В статье продемонстрированы данные, позволяющие заметить трансформацию научных публикаций с 1996 по 2017 года на примере статей, опубликованных в журнале «Science». Если исходить из предположения, что журнал «Science» является одним из ведущих, высокорейтинговых журналов, отображающих состояние и тенденции мировой науки, и он вполне репрезентативен в контексте поставленной задачи, то рассуждения о состоянии, полученные на интуитивном уровне и изложенные в начале настоящей статьи, нашли некоторое фактическое подтверждение при использовании для анализа модели кластеризации документов на основе классов слов определенной направленности.
Таким образом с высокой долей вероятности можно констатировать, что представленное во введении предположение о том, что научные публикации за последние 20 лет стали более политизированными и коммерциализированными подтвердилось. Кроме того, показана тенденция смещения в последние 20 лет научного интереса в прикладные практические области при снижении числа публикаций, основанных на результатах исследований теоретического и фундаментального характера.
Библиография
1. Geden, O. Climate advisers must maintain integrity, Nature, 2015, vol. 521, no. 7550, pp. 27—28.
2. Horgan, J. The End Of Science: Facing The Limits Of Knowledge In The Twilight Of The Scientific Age. NY, Basic Books, 2015, 368 pp.
3. Jones, K. S. A statistical interepretation of tern specificity and its application in retrieval, Journal of Documentation, MCB University Press, 2004, vol. 60, no. 5, pp. 493—502.
4. MacQueen, J. B. Some Methods for classification and Analysis of Multivariate Observations, 5-th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, University of California Press, 1967, pp. 281—297.
5. Vernikos, G. S. The pyramid of knowledge, Nature Reviews. Microbiology, 2010, vol. 8, no. 2, pp. 91.
6. Zhai, C. X., Massung, S. Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining, NY, Association for Computing Machinery and Morgan & Claypool, 2016, 531 p.
Источник: Программная инженерия. 2018. Т.9. №2.
Рекомендуем прочесть
 Великий библиометрический джихад
Великий библиометрический джихад Что если необычайно прибыльная сфера научных публикаций вредит самой науке?
Что если необычайно прибыльная сфера научных публикаций вредит самой науке? Науку коррумпируют не только фармкомпании, но капитализм в целом
Науку коррумпируют не только фармкомпании, но капитализм в целом Вот как конкуренция делает рецензирование менее справедливым
Вот как конкуренция делает рецензирование менее справедливым «Жизнь после санкций»
«Жизнь после санкций» Чирлидинг повестки дня: как пресса кроет науку
Чирлидинг повестки дня: как пресса кроет науку Технологии увеличения индекса Хирша и развитие имитационной науки
Технологии увеличения индекса Хирша и развитие имитационной науки![Ложные практики в полевой биологии – что [с ними] может быть сделано?](http://www.socialcompas.com/wp-content/uploads/2014/01/7-150x150.jpg) Ложные практики в полевой биологии – что [с ними] может быть сделано?
Ложные практики в полевой биологии – что [с ними] может быть сделано?
